C# Channels - Async Data Pipelines
In this article, we’ll learn how to efficiently process data in a non-blocking way using the pipeline pattern. We’ll construct composable and testable pipelines using .NET’s channels, and see how to perform cancellation and deal with errors. If you’re new to the concept of channels, I suggest checking out part 1 and part 2 of the series first.
Pipelines
A pipeline is a concurrency model where a job is handled through several processing stages. Each stage performs a part of the full job and when it’s done, it forwards it to the next stage. It also runs in a separate thread and shares no state with the other stages.

The generator delegates the jobs, which are being processed through the pipeline. For example, we can represent the pizza preparation as a pipeline, consisting of the following stages:
- Pizza order (Generator)
- Prepare dough
- Add toppings
- Bake in oven
- Put in a box
Stages start executing as soon as their input is ready, that is, when stage 2 adds toppings to pizza 1, stage 1 can prepare the dough for pizza 2, when stage 4 puts the baked pizza 1 in a box, stage 1 might be preparing the dough for pizza 3 and so on.
Implementing a Channel-based Pipeline
Each pipeline starts with a generator method, which initiates jobs by passing it to the stages. The intermediate stages are also methods that run concurrently. Channels serve as a transport mechanism between the stages. A stage takes a channel as an input, performs some work on each data item it asynchronously reads, and passes the result to an output channel. The purpose of a stage is to do one job and do it well.
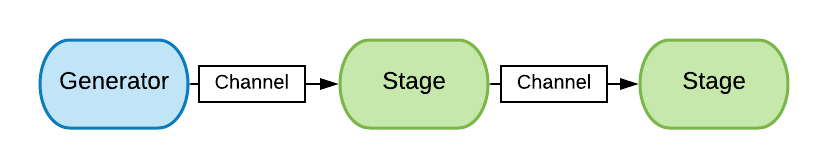
To see it in action, we’re going to implement a program that efficiently counts the lines of code in a project.
The Generator - Enumerate the Files
The initial stage of our pipeline would be to enumerate recursively the files in the workspace. We implement it as a generator.
ChannelReader<string> GetFilesRecursively(string root)
{
var output = Channel.CreateUnbounded<string>();
async Task WalkDir(string path)
{
foreach (var file in Directory.GetFiles(path))
await output.Writer.WriteAsync(file);
var tasks = Directory.GetDirectories(path).Select(WalkDir);
await Task.WhenAll(tasks.ToArray());
}
Task.Run(async () =>
{
await WalkDir(root);
output.Writer.Complete();
});
return output;
}
We perform a depth-first traversal of the directory and its subdirectories and write each file name we encounter to the output channel. When we’re done with the traversal, we mark the channel as complete so the consumer (the next stage) knows when to stop reading from it.
Stage 1 - Keep the Source Files
Stage 1 is going to determine whether the file contains source code or not. The ones that don’t should be discarded.
ChannelReader<FileInfo> FilterByExtension(
ChannelReader<string> input, HashSet<string> exts)
{
var output = Channel.CreateUnbounded<FileInfo>();
Task.Run(async () =>
{
await foreach (var file in input.ReadAllAsync())
{
var fileInfo = new FileInfo(file);
if (exts.Contains(fileInfo.Extension))
await output.Writer.WriteAsync(fileInfo);
}
output.Writer.Complete();
});
return output;
}
This stage takes an input channel (produced by the generator) from which it asynchronously reads the file names. For each file, it gets its metadata and checks whether the extension belongs to the set of the source code file extensions. It also transforms the input, that is, for each file that satisfies the condition, it writes a FileInfo object to the output channel.
Stage 2 - Get the Line Count
This stage is responsible for counting the number of lines in each file.
ChannelReader<(FileInfo file, int lines)>
GetLineCount(ChannelReader<FileInfo> input)
{
var output = Channel.CreateUnbounded<(FileInfo, int)>();
Task.Run(async () =>
{
await foreach (var file in input.ReadAllAsync())
{
var lines = CountLines(file);
await output.Writer.WriteAsync((file, lines));
}
output.Writer.Complete();
});
return output;
}
We write a tuple of type (FileInfo, int) which is a pair of the file metadata and its number of lines. The int CountLines(FileInfo file) method is straightforward, you can check out the implementation below.
Expand CountLines
int CountLines(FileInfo file)
{
using var sr = new StreamReader(file.FullName);
var lines = 0;
while (sr.ReadLine() != null)
lines++;
return lines;
}
The Sink Stage
Now we’ve implemented the stages of our pipeline, we are ready to put them all together.
var fileGen = GetFilesRecursively("path_to/node_modules");
var sourceCodeFiles = FilterByExtension(
fileGen, new HashSet<string> { ".js", ".ts" });
var counter = GetLineCount(sourceCodeFiles);
The sink stage processes the output from the last stage of the pipeline. Unlike the generator, which doesn’t consume, but only produces, the sink only consumes but doesn’t produce. That’s where our pipeline comes to an end.
var totalLines = 0;
await foreach (var item in counter.ReadAllAsync())
{
Console.WriteLine($"{item.file.FullName} {item.lines}");
totalLines += item.lines;
}
Console.WriteLine($"Total lines: {totalLines}");
/Users/denis/Workspace/proj/index.js 155
/Users/denis/Workspace/proj/main.ts 97
/Users/denis/Workspace/proj/tree.ts 0
/Users/denis/Workspace/proj/lib/index.ts 210
Total lines: 462
Error Handling
We’ve covered the happy path, however, our pipeline might encounter malformed or erroneous inputs. Each stage has its own notion of what an invalid input is, so it’s its own responsibility to deal with it. To achieve good error handling, our pipeline needs to satisfy the following:
- Invalid input should not propagate to the next stage
- Invalid input should not cause the pipeline to stop. The pipeline should continue to process the inputs thereafter.
- The pipeline should not swallow errors. All the errors should be reported.
We’re going to modify stage 2 which counts the lines in a file. Our definition for invalid input is an empty file. Our pipeline should not pass them forward and instead, it should report the existence of such files. We solve that by introducing a second channel that emits the errors.
- ChannelReader<(FileInfo file, int lines)> GetLineCount(
+ (ChannelReader<(FileInfo file, int lines)> output,
+ ChannelReader<string> errors)
GetLineCount(ChannelReader<FileInfo> input)
{
var output = Channel.CreateUnbounded<(FileInfo, int)>();
+ var errors = Channel.CreateUnbounded<string>();
Task.Run(async () =>
{
await foreach (var file in input.ReadAllAsync())
{
var lines = CountLines(file);
- await output.Writer.WriteAsync((file, lines));
+ if (lines == 0)
+ await errors.Writer.WriteAsync(
+ $"[Error] Empty file {file}");
+ else
+ await output.Writer.WriteAsync((file, lines));
}
output.Writer.Complete();
+ errors.Writer.Complete();
});
- return output;
+ return (output, errors);
}
We’ve created a second channel for errors and changed the signature of the method so it returns both the output and the error channels. Empty files are not passed to the next stage, we’ve provided a mechanism to report them using the error channel and after we get an invalid input, our pipeline continues processing the next ones.
var fileGen = GetFilesRecursively("path_to/node_modules");
var sourceCodeFiles = FilterByExtension(
fileGen, new HashSet<string> { ".js", ".ts" });
var (counter, errors) = GetLineCount(sourceCodeFiles);
var totalLines = 0;
await foreach (var item in counter.ReadAllAsync())
totalLines += item.lines;
Console.WriteLine($"Total lines: {totalLines}");
await foreach (var errMessage in errors.ReadAllAsync())
Console.WriteLine(errMessage);
/Users/denis/Workspace/proj/index.js 155
/Users/denis/Workspace/proj/main.ts 97
/Users/denis/Workspace/proj/lib/index.ts 210
Total lines: 462
[Error] Empty file /Users/denis/Workspace/proj/tree.ts
Cancellation
Similarily to the error handling, the stages being independent means that each has to handle cancellation on their own. To stop the pipeline, we need to prevent the generator from delegating new jobs. Let’s make it cancellable.
ChannelReader<string> GetFilesRecursively(
string root, CancellationToken token = default)
{
var output = Channel.CreateUnbounded<string>();
async Task WalkDir(string path)
{
if (token.IsCancellationRequested)
throw new OperationCanceledException();
foreach (var file in Directory.GetFiles(path))
await output.Writer.WriteAsync(file, token);
var tasks = Directory.GetDirectories(path).Select(WalkDir);
await Task.WhenAll(tasks.ToArray()));
}
Task.Run(async () =>
{
try
{
await WalkDir(root);
}
catch (OperationCanceledException) { Console.WriteLine("Cancelled."); }
finally { output.Writer.Complete(); }
});
return output;
}
The change is straightforward, we need to handle the cancellation in a try/catch block and not forget to close the output channel. Keep in mind that canceling only the initial stage will leave the next stages running with the existing jobs which might not always be desired, especially if the stages are long-running. Therefore, we have to make them able to handle cancellation as well.
var cts = new CancellationTokenSource();
cts.CancelAfter(TimeSpan.FromSeconds(2));
var fileSource = GetFilesRecursively("path_to/node_modules", cts.Token);
...
Dealing with Backpressure
The term backpressure is borrowed from fluid dynamics and relates to to the software systems’ dataflow. In our examples, the stages execute concurrently but this doesn’t guarantee an optimal performance. Let’s revisit the pizza example. It takes a longer time to bake the pizza than to add the toppings. This becomes an issue when we have to process a large number of pizza orders as we’re going to end up with many pizzas with their toppings added, waiting to be baked, but our oven bakes only one at a time. We can solve this by getting a larger oven, or even multiple ovens.
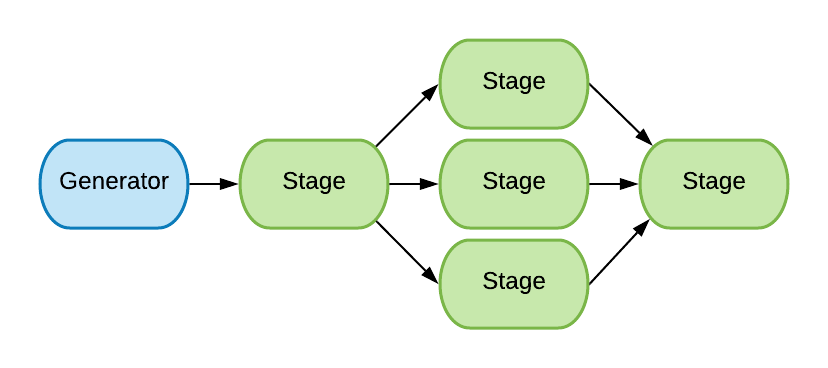
In the line-counter example, the stage where we read the file and count its lines might cause might experience backpressure because reading a sufficiently large file (stage 2) is slower than retreiving a file metadata (stage 1). It makes sense to increase the capacity of this stage and that’s where Split<T> and Merge<T> which we discussed in part 1 come into use. We’ll summarize them.
Split
Split<T> is a method that takes an input channel and distributes its messages amongst several outputs. That way we can let several threads concurrently handle the message processing.

Expand Split<T> implementation
IList<ChannelReader<T>> Split<T>(ChannelReader<T> input, int n)
{
var outputs = new Channel<T>[n];
for (var i = 0; i < n; i++)
outputs[i] = Channel.CreateUnbounded<T>();
Task.Run(async () =>
{
var index = 0;
await foreach (var item in input.ReadAllAsync())
{
await outputs[index].Writer.WriteAsync(item);
index = (index + 1) % n;
}
foreach (var ch in outputs)
ch.Writer.Complete();
});
return outputs.Select(ch => ch.Reader).ToArray();
}
We’re going to use it to distribute the source code files among 5 channels which will let us process up to 5 files simultaneously. This is similar to when supermarkets open additional checkout lines when there’re a lot of customers waiting.
var fileSource = GetFilesRecursively("path_to/node_modules");
var sourceCodeFiles =
FilterByExtension(fileSource, new HashSet<string> {".js", ".ts" });
var splitter = Split(sourceCodeFiles, 5);
Merge
Merge<T> is the opposite operation. It takes multiple input channels and consolidates them in a single output.

Expand Merge<T> implementation
ChannelReader<T> Merge<T>(params ChannelReader<T>[] inputs)
{
var output = Channel.CreateUnbounded<T>();
Task.Run(async () =>
{
async Task Redirect(ChannelReader<T> input)
{
await foreach (var item in input.ReadAllAsync())
await output.Writer.WriteAsync(item);
}
await Task.WhenAll(inputs.Select(i => Redirect(i)).ToArray());
output.Writer.Complete();
});
return output;
}
During Merge<T>, we read concurrently from several channels, so this is the stage that we need to tweak a little bit and perform the line counting.
We introduce, CountLinesAndMerge which doesn’t only redirect, but also transforms.
ChannelReader<(FileInfo file, int lines)>
CountLinesAndMerge(IList<ChannelReader<FileInfo>> inputs)
{
var output = Channel.CreateUnbounded<(FileInfo file, int lines)>();
Task.Run(async () =>
{
async Task Redirect(ChannelReader<FileInfo> input)
{
await foreach (var file in input.ReadAllAsync())
await output.Writer.WriteAsync((file, CountLines(file)));
}
await Task.WhenAll(inputs.Select(Redirect).ToArray());
output.Writer.Complete();
});
return output;
}
The error handling and the cancellation are omitted for the sake of brevity, however, we’ve already seen how to implement them. Now we’re ready to build our pipeline.
var fileSource = GetFilesRecursively("path_to/node_modules");
var sourceCodeFiles =
FilterByExtension(fileSource, new HashSet<string> {".js", ".ts"});
- var counter = GetLineCount(sourceCodeFiles);
+ var counter = CountLinesAndMerge(Split(sourceCodeFiles, 5));
TPL Dataflow
The TPL Dataflow library is another option for implementing pipelines or even meshes in .NET. It has a powerful, high-level API but compared to the channel-based approach also comes with a steeper learning curve and provides less control. Personally, I think that deciding between the two should strongly depend on the case. If you prefer a simpler API and more control, the lightweight channels would be the way to go. If you want a high-level API with more features, check out TPL Dataflow.
Conclusion
We defined the pipeline concurrency model and learned how to use it to implement flexible, high-performance data processing workflows. We learned how to deal with errors, perform cancellation as well as how to apply some of the channel techniques (multiplexing and demultiplexing), described in the previous articles, to handle backpressure.
Besides performance, pipelines are also easy to change. Each stage is an atomic part of the composition that can be independently modified, replaced, or removed as long as we keep the method (stage) signatures intact. For example, it’s trivial to convert the line counter pipeline to search for patterns in text, say parsing log files etc. by replacing the line counter stage with another one.
We can see how it can lead to a significant reduction in our code’s cyclomatic complexity as well as making it easier to test. Each stage is simply a method with no side effects, which can be unit tested in isolation. Stages have a single responsibility, which makes them easier to reason about, thus we can cover all the possible cases.
References & Further Reading
- GitHub Repo with the interactive examples
- Part 1: C# Channels - Publish / Subscribe workflows
- Part 2: C# Channels - Timeout and Cancellation
- The graphics are implemented using Lucidchart